Anthropic ser att vana Claude-användare lyckas oftare
Miljon samtal från februari 2026 visar att framgång ökar med erfarenhet även när uppgift och land vägs in, vinsten hamnar hos dem som kan iterera och betala för bättre modeller när Claude.ai fylls av privata småärenden och arbetet flyttar till företagens verktygskedjor
Bilder
 Image description
the-decoder.com
Image description
the-decoder.com
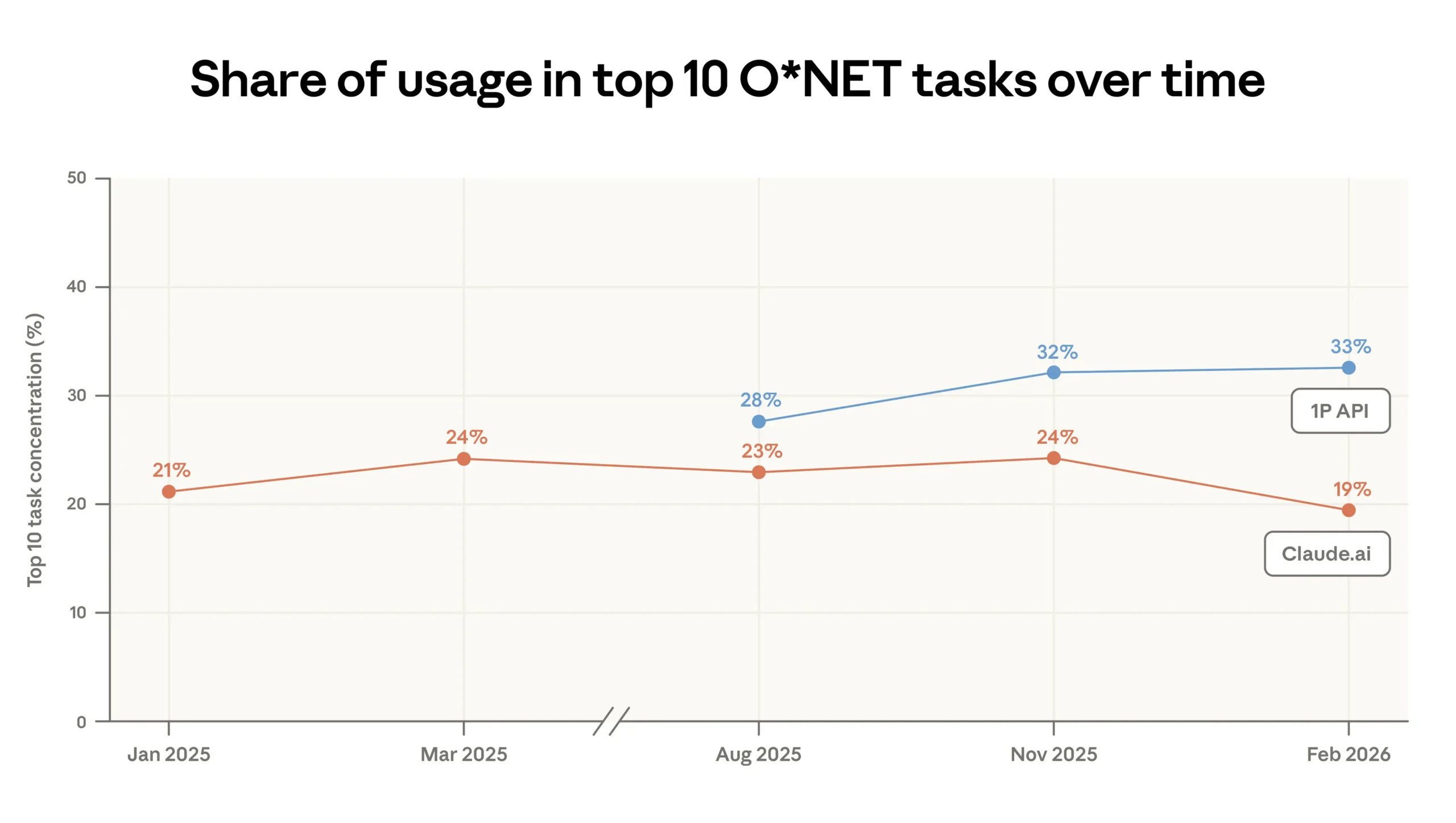 Usage on Claude.ai is becoming more widespread: the share of the ten most common tasks fell from 24 to 19 percent, while it rose to 33 percent in the API. | Image: Anthropic
Anthropic
Usage on Claude.ai is becoming more widespread: the share of the ten most common tasks fell from 24 to 19 percent, while it rose to 33 percent in the API. | Image: Anthropic
Anthropic
 Usage on Claude.ai is spreading out: the share of the ten most common tasks dropped from 24 to 19 percent, while API concentration rose to 33 percent. | Image: Anthropic
Anthropic
Usage on Claude.ai is spreading out: the share of the ten most common tasks dropped from 24 to 19 percent, while API concentration rose to 33 percent. | Image: Anthropic
Anthropic
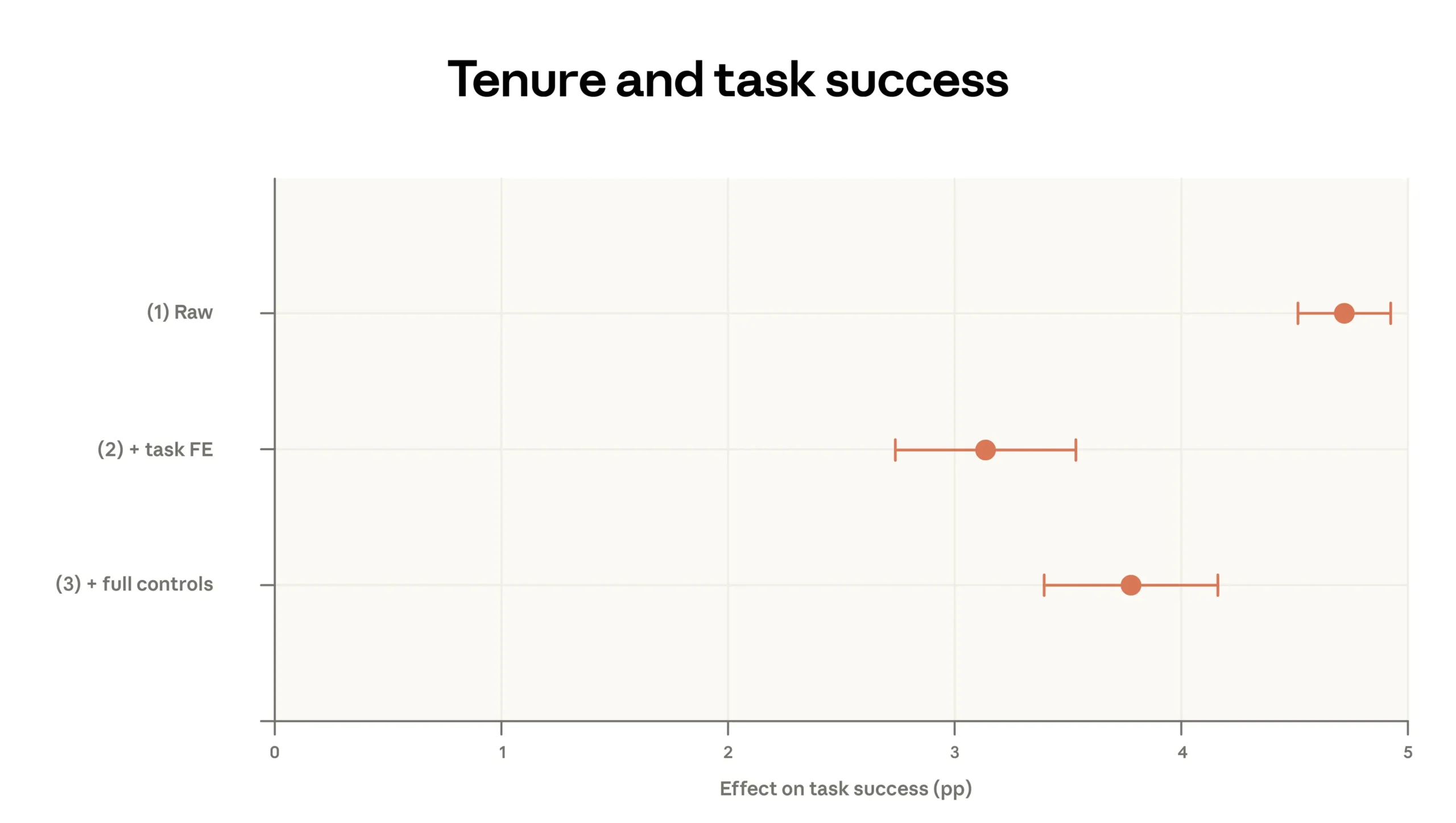 Anthropic measures success by having Claude evaluate anonymized transcripts to determine whether a conversation achieved its goal. The experience effect comes out to about four percentage points. | Image: Anthropic
Anthropic
Anthropic measures success by having Claude evaluate anonymized transcripts to determine whether a conversation achieved its goal. The experience effect comes out to about four percentage points. | Image: Anthropic
Anthropic
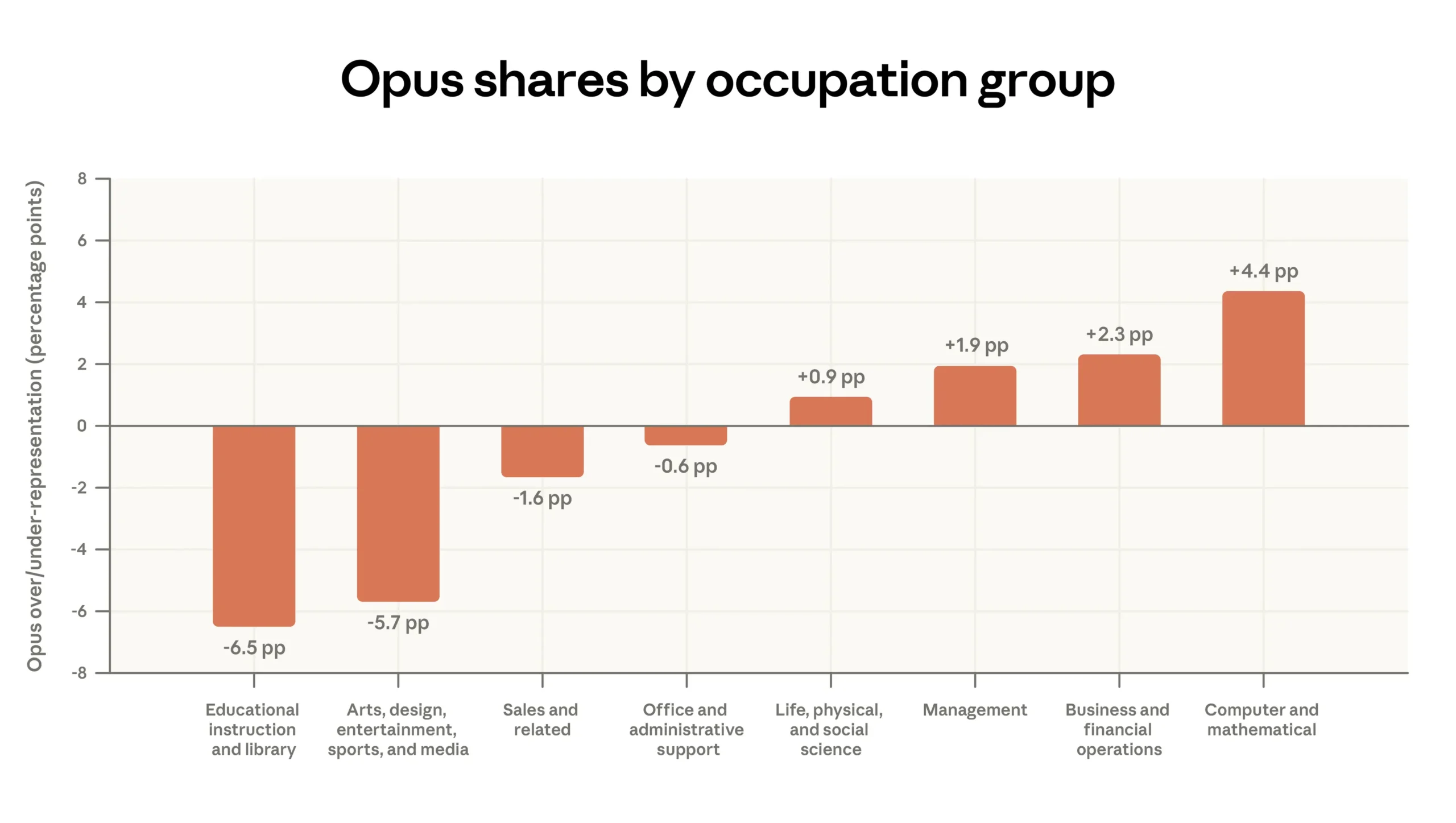 Users pick Opus specifically for demanding work. For computer and math tasks, Opus usage runs 4.4 percentage points above average; for educational tasks, it sits 6.5 points below. | Image: Anthropic
Anthropic
Users pick Opus specifically for demanding work. For computer and math tasks, Opus usage runs 4.4 percentage points above average; for educational tasks, it sits 6.5 points below. | Image: Anthropic
Anthropic
Anthropic uppger att en miljon samtal med Claude från februari 2026 visar ett enkelt mönster: ju längre människor använder modellen, desto bättre blir de på att få den att leverera. I företagets senaste rapport i serien Economic Index framgår att erfarna användare är omkring fyra procentenheter mer benägna att nå sitt mål än nybörjare, även när man tar hänsyn till uppgiftstyp, modellval och land, enligt The Decoders sammanställning av uppgifterna.
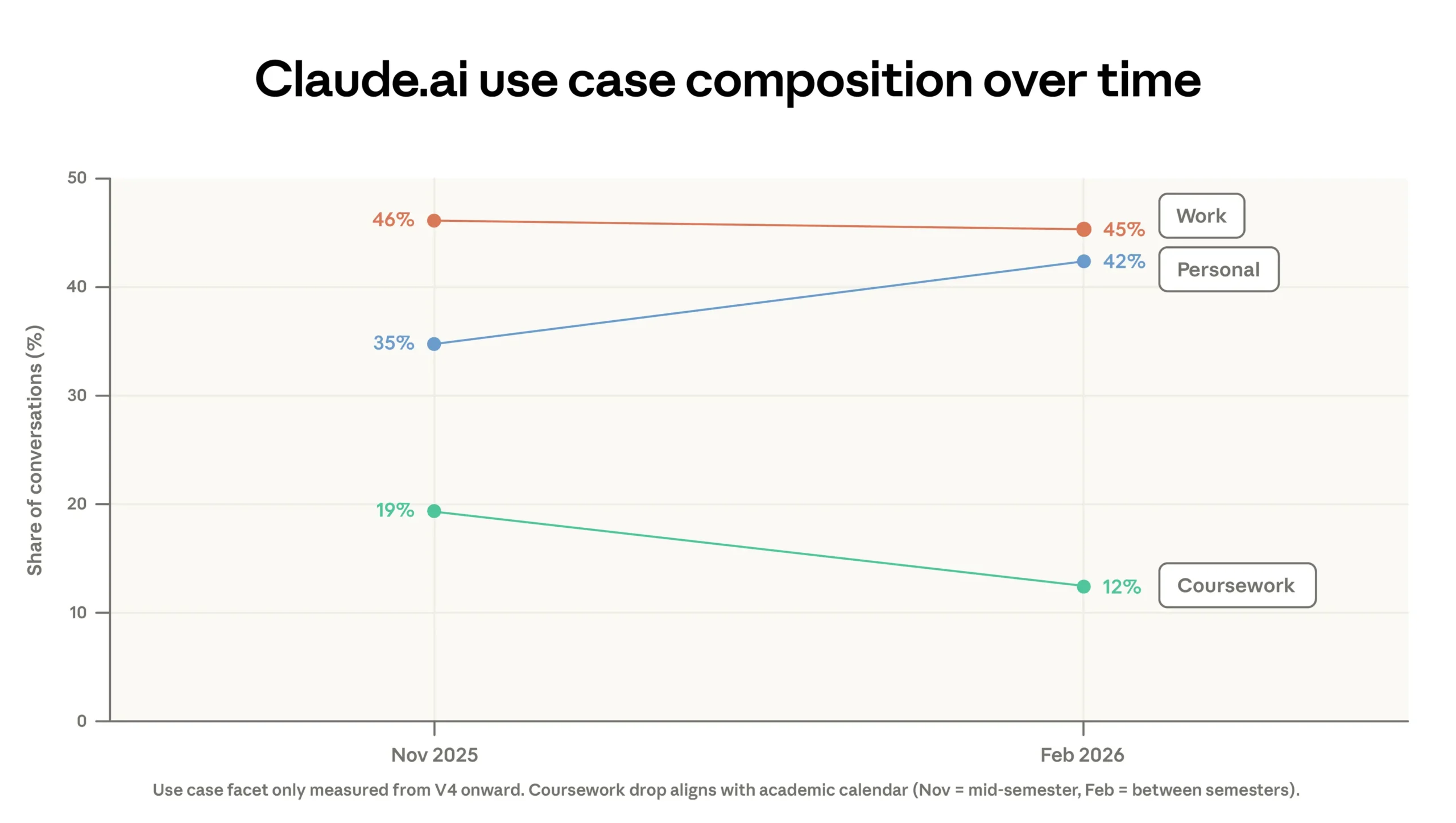
Samtidigt förändras fördelningen av vad folk gör med Claude. Programmering är fortfarande den största enskilda kategorin med 35 procent av användningen, men en större del av detta flyttar in i Anthropics gränssnittsprogram för programmering, däribland Claude Code. Den konsumentinriktade webbplatsen Claude.ai fylls i stället av enklare personliga önskemål. Andelen ”personliga” uppmaningar har ökat från 35 till 42 procent sedan förra rapporten, och det genomsnittliga ”ekonomiska värdet” av uppgifter på Claude.ai – uppskattat via timlöner i de yrken som kopplas till uppgifterna – har sjunkit något, från cirka 49 till 48 dollar i timmen.
Den här inlärningskurvan spelar roll eftersom rapporten beskriver två skilda sätt som artificiell intelligens tar plats i organisationer. Nya användare behandlar ofta modellen som en varuautomat: en uppmaning in, ett svar ut. Erfarna användare arbetar i stället iterativt, omformulerar, granskar och samarbetar. Anthropic uppger att veteraner mer sällan nöjer sig med en enda instruktion och oftare förfinar sin begäran genom fram och tillbaka, och att de använder verktyget mer för yrkesmässigt arbete. I den mest erfarna änden blir uppgifterna tydligt ”inne i arbetsflödet”: åtgärder i Git, genomgång av manus och forskning om artificiell intelligens, snarare än dikter och småfrågor.
Skillnaden handlar inte bara om smak, utan om hävstång. Ett övertag på fyra procentenheter i lyckandefrekvens växer i betydelse när ett verktyg används dussintals gånger i veckan, och när bättre svar innebär snabbare beslut, färre fel och större trygghet att automatisera närliggande steg. Det gynnar också dem som redan har ordnade processer och ämneskunskap – eftersom modellens resultat fortfarande måste specificeras, kontrolleras och fogas in. I praktiken flyttar det värde från slagord om ”artificiell intelligens för alla” till de personer som kan översätta ett rörigt verksamhetsproblem till en följd av kontrollerbara steg.
Anthropics uppgifter om modellval pekar åt samma håll. Betalande användare på Claude.ai väljer oproportionerligt ofta den mer kapabla modellen Opus för mer krävande arbete (55 procent av programmeringsuppgifterna mot 45 procent av utbildningsuppgifterna), medan användare av gränssnittsprogrammeringen reagerar ännu starkare på uppgifternas svårighetsgrad. Det är delvis teknisk mognad, men också budgetmakt: de som kan motivera högre kostnad per symbolenhet tenderar att sitta närmare intäkter, risk eller ingenjörsarbete.
Anthropic ramar in resultaten som en varning för växande ojämlikhet. Rapportens egna siffror antyder något mer handfast: fördelen tillfaller erfarna användare som arbetar i flera omgångar, och organisationer som kan betala för bättre modeller och bygga in dem i befintliga verktygskedjor.
I februari stod de tio vanligaste uppgifterna på Claude.ai för 19 procent av trafiken, ned från 24 procent tre månader tidigare. Den långa svansen växer – men de sammansatta vinsterna tycks koncentreras där uppmaningarna kommer med kontrollistor, kodbaser och någon som faktiskt får betalt för att bry sig om resultatet.