Språkmodeller klarar nu cyberangrepp som tar säkerhetsexperter tre timmar
Ny studie från Lyptus mäter offensiv förmåga med METR-metoden och ser fördubbling var 5,7:e månad sedan 2024, mer beräkningskraft och större tokenbudget gör testerna missvisande när angripare kan köpa sig tid
Bilder
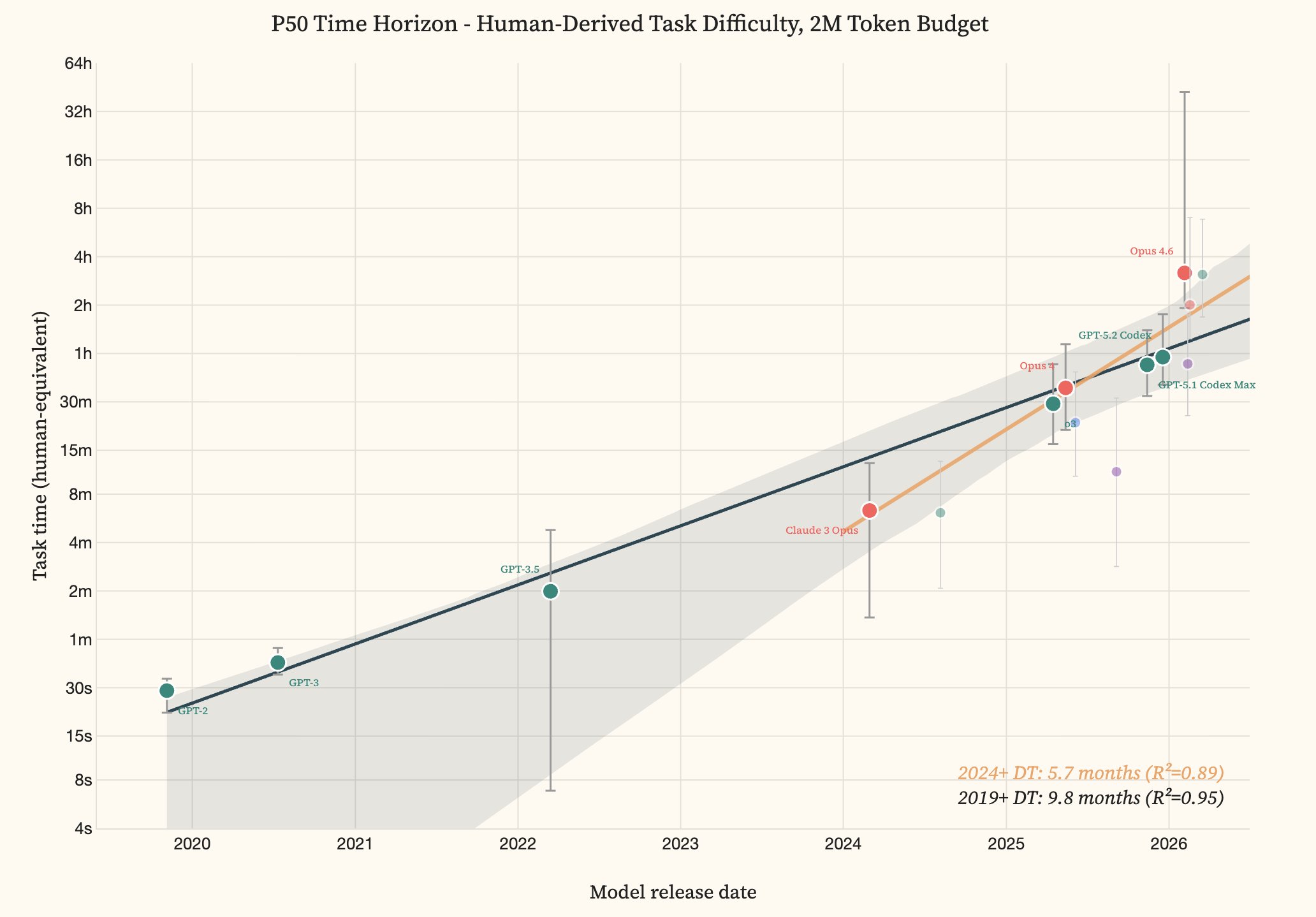 Offensive cyber capability of AI models over time: From GPT-2 (2019) to Opus 4.6 and GPT-5.3 Codex (2026), the time horizon grew from 30 seconds to roughly three hours. The doubling time accelerated from 9.8 months (since 2019) to 5.7 months (since 2024). | Image: Lyptus Research
Lyptus Research
Offensive cyber capability of AI models over time: From GPT-2 (2019) to Opus 4.6 and GPT-5.3 Codex (2026), the time horizon grew from 30 seconds to roughly three hours. The doubling time accelerated from 9.8 months (since 2019) to 5.7 months (since 2024). | Image: Lyptus Research
Lyptus Research
Modeller för artificiell intelligens kan nu genomföra delar av cyberangrepp som tar mänskliga yrkespersoner omkring tre timmar, och tiden det tar för de mest avancerade systemen att nå den nivån krymper snabbt. En ny studie från säkerhetsforskningsföretaget Lyptus Research visar att den offensiva cyberförmågan i praktiken har fördubblats ungefär var sjätte månad sedan 2024 – en tydlig acceleration jämfört med den långsammare utveckling som observerats sedan 2019.
Studien, som refereras av The Decoder, använder METR:s så kallade tidshorisontmetod. I stället för att fråga om en modell kan hacka ett mål ”i det fria” mäter forskarna hur lång tid en jämförbar mänsklig expert skulle behöva för att lösa en kurerad uppsättning offensiva säkerhetsuppgifter som modellen klarar med en viss framgångsgrad. Lyptus prövade 291 uppgifter med tio yrkesverksamma säkerhetsexperter och jämförde därefter flera generationer av modeller, från system i samma epok som GPT-2 till dagens mest avancerade verktyg.
Huvudpoängen är inte ett enskilt resultat för en viss modell, utan lutningen på utvecklingskurvan. Lyptus uppskattar att fördubblingstiden för offensiv förmåga var 9,8 månader från 2019, men har pressats ned till 5,7 månader sedan 2024. Studien finner också att större ”symbolbudgetar” – i praktiken mer beräkningskraft och mer utrymme för försök och misstag – ger kraftiga språng i vad modellerna kan åstadkomma. GPT-5.3 Codex går exempelvis från en tidshorisont på ungefär tre timmar till mer än tio timmar när budgeten höjs från två miljoner symboler till tio miljoner. Det antyder att många utvärderingar underskattar verklig prestanda i situationer där angripare kan lägga mer beräkningskraft på långa, upprepade försök.
Skillnaden mellan öppna och slutna modeller minskar men är fortfarande mätbar. Enligt Lyptus ligger öppna modeller efter slutna med omkring 5,7 månader på detta mått. I ett kapprustningsläge spelar en sådan eftersläpning roll, men den ger inget stabilt skydd för mindre organisationer när metoder och verktyg väl sprids.
För försvarare innebär detta att ”med artificiell intelligens” inte längre bara betyder en pratrobot som skriver nätfiskebrev. Om modeller i ökande grad kan hantera flerstegsutnyttjanden med meningsfulla framgångsgrader flyttas flaskhalsen mot åtkomst, operativ säkerhet och ekonomin i att skala angrepp – inklusive vem som har råd med den beräkningskraft som krävs för långa, iterativa angreppsförsök. För programvaruleverantörer och aktörer som driver samhällsviktig infrastruktur höjer det värdet av grundläggande hygien som ofta underfinansieras: att täppa till kända sårbarheter, segmentera nät och minska okontrollerad spridning av inloggningsuppgifter.
Lyptus har publicerat sina data på GitHub och Hugging Face. Kurvan de ritar upp är brant, och kostnaderna för att ha fel om utvecklingstakten fördelas inte jämnt.