Google tredubblar lokal textgenerering i Gemma 4
Spekulativ avkodning med små förhandsmodeller låter stora modellen godkänna flera ord i samma beräkning, datacentermetod säljs som batterisparande mobilfunktion och Gemma får samtidigt friare Apache 2.0-licens
Bilder
 Credit:
Google
Credit:
Google
 Photo of Ryan Whitwam
arstechnica.com
Photo of Ryan Whitwam
arstechnica.com
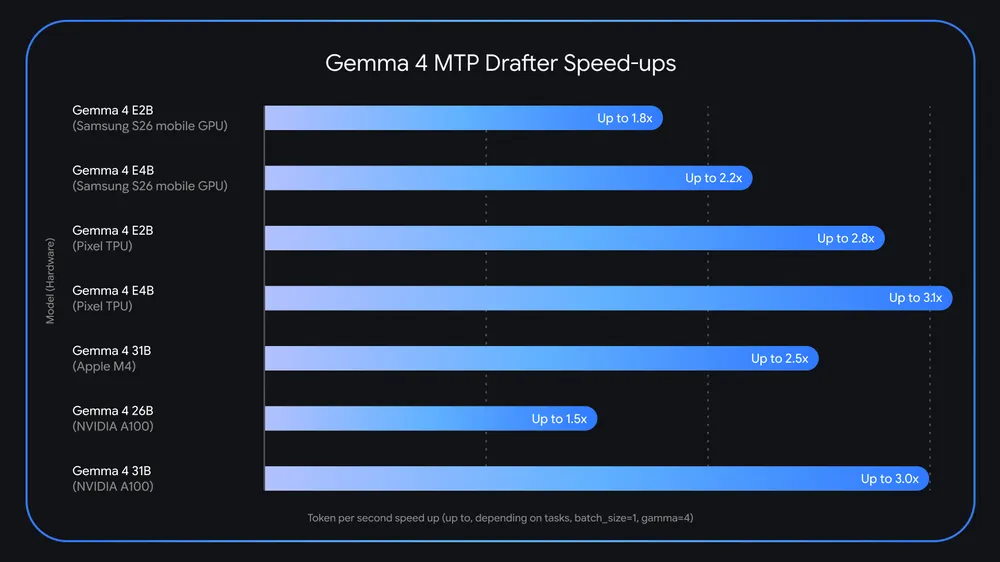
Google börjar leverera nya verktyg till sina öppna Gemma 4‑modeller som enligt Ars Technica kan göra lokal textframställning upp till tre gånger snabbare. Förbättringen kommer via så kallade flertokensförutsägare, ”utkastare”, som använder spekulativ avkodning: en mindre modell gissar flera kommande tecken i följd, och en större modell kontrollerar dem parallellt. Google säger sig se tydliga fartökningar både på Pixel‑telefoner och på Apples M4‑datorer, och gör därmed en optimering som annars hör hemma i serverhallar till ett säljargument för vanliga konsumentapparater.
Gemma hamnar i ett besvärligt mellanläge för Google. Gemini är anpassad för företagets egna beräkningskluster med specialkretsar, medan Gemma marknadsförs mot utvecklare som vill köra modeller på egen utrustning. Den målgruppen bryr sig mindre om topplaceringar i mätningar och mer om huruvida körningen faktiskt fungerar på en bärbar dator, en arbetsstation eller en telefon utan att batteriet töms och varje mening tar sekunder att få fram. Ars Technica beskriver den praktiska begränsningen: tecken framställs självåterkopplande, ett i taget, och på konsumentsystem står beräkningsenheterna ofta sysslolösa medan modellens parametrar flyttas från minnet. Utkastarmodellen försöker fylla denna dödtid genom att billigt ta fram sannolika teckenkedjor, som huvudmodellen sedan får godkänna eller underkänna.
Det tekniska upplägget spelar roll eftersom det ändrar ekonomin för ”lokal artificiell intelligens”. Om huvudmodellen kan kontrollera flera utkasttecken i ett enda framåtriktat beräkningssteg, och dessutom ändå avge ytterligare ett tecken på vanligt sätt, sjunker kostnaden per framställt tecken utan att modellvikterna ändras. Det är lockande för utvecklare som betalar för grafikprocessors tid, men också för användare som inte vill skicka sina frågor till en molntjänst. Google trycker på just den poängen och hänvisar till bättre batteritid i mobiler, där bortkastad beräkning direkt blir värme och strypning av prestanda.
Ars Technica noterar också att Google har flyttat Gemma 4 till licensen Apache 2.0, som är mer tillåtande än de speciallicenser som ofta krånglar till ”öppna” modellsläpp. Tillsammans med möjligheter till kvantisering är budskapet att Gemma ska kunna sättas i drift på fler ställen, och att prestanda kan vinnas genom avkodningsstrategi snarare än genom att köpa större acceleratorkretsar. För europeiska användare som vill minska beroendet av amerikanska moln och deras villkor är detta i sak en intressant utveckling, även om den samtidigt knyter ekosystemet närmare en dominerande leverantör.
Googles egna siffror varierar mellan apparater. Företaget anger ungefär 2,8 till 3,1 gånger snabbare prestanda för mindre Gemma‑varianter på Pixel‑hårdvara och omkring 2,5 gånger för modellen med 31 miljarder parametrar på Apples M4‑kretsar. Påståendena är formulerade som ”upp till”, men den konkreta förskjutningen är att lokal körhastighet nu marknadsförs som en egenskap i sig, inte som en kompromiss.
Utkastarmodellerna är mycket små jämfört med huvudmodellen, i storleksordningen tiotals miljoner parametrar. Det är ändå de som gör att en process som annars tar ett tecken i taget börjar likna en mer löpande kedja, där flera steg kan förberedas och kontrolleras i klump.